作者:Xu Chu, Zhijie Tan, Hanlin Xue, Guanyu Wang, Tong Mo, Weiping Li
单位:School of Software and Microelectronics, Peking University
来源:Association for Computational Linguistics 2025
时间:2025.07.27
链接:[Domaino1s: Guiding LLM Reasoning for Explainable Answers
in High-Stakes Domains]
一. 研究背景
在一些高风险的专业知识领域中,对可解释推理的刚性需求非常高:
许多领域模型倾向输出“简短结论”,导致解释性不足。
在高风险决策中,缺乏解释会降低信任与可审计性。
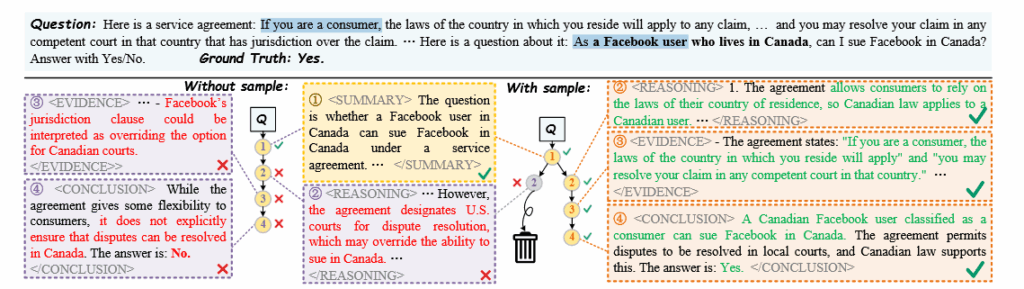
CoT能提供分步推理,但单次生成缺少纠错机制:前面一步错,后续会沿错误路径继续推理。
高风险场景下,错误推理链可能引入法律与伦理风险,需要“可解释 + 可纠错”的推理范式。
在这个研究背景下,本文提出了一个面向高风险领域的可解释多步推理框架Domaino1s:监督微调让模型学会结构化推理,再用树搜索式的多路径探索做一定程度的自纠错,同时提出一个评价解释性的指标 PROOF-Score,让大模型去做一些近似专家化的评估。
二. 论文概要
这个框架提出两个变体:Domaino1s-finance 与 Domaino1s-legal,分别用于股票投资建议与法律推理问答。训练方面,用 GPT-4o 生成结构化 CoT 数据进行监督微调,构造时用特殊 token 标注步骤,但微调时移除这些 token,让模型学会自主组织中间步骤。推理方面,提出 Selective Tree Exploration,用“每一步推理的平均困惑度”判断是否需要扩展新路径并选择最优分支,在性能与推理耗时间折中。评估方面:除准确率外,引入 PROOF-Score评估解释质量。

三. 方法框架
1. 构建领域 CoT 训练数据:
1) s用 GPT-4o 生成领域化推理过程,构建 CoT-stock-2k 与 CoT-legal-2k,用于激发模型在特定领域的推理能力。
2) 构造阶段使用26个特殊 token(如 )显式标记不同推理步骤;微调时移除 token,使模型在推理时“自选步骤 + 自组织链条”。
本文给出观点:小规模样本的目的不是灌入大量领域事实,而是让模型学会领域内如何推理。
2.Domaino1s 方法框架:SFT 激发推理 + Tree Search 纠错 + PROOF 评价解释
1) 领域 CoT 数据(GPT-4o 生成 + 特殊 token 标注)
2) 监督微调 SFT(移除 token → 自主组织步骤)
3) 推理生成 Selective TreeExploration(纠错)
4) 评估:Accuracy + PROOF-Score(RC/DS/FA)
RC:推理是否完整且逻辑连贯
DS:领域安全/合规性(避免不当建议或风险输出)
FA:事实准确性(引用/陈述是否正确)
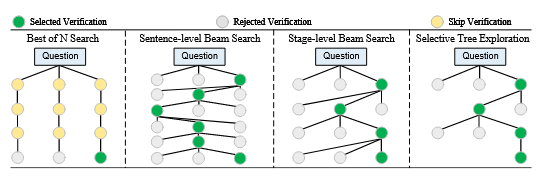
3. Selective Tree Exploration:用“困惑度阈值”触发局部重采样
1) 把推理链拆成多个“步骤(step)”,每个步骤是树中的节点。
2) 为每个步骤计算 token 平均困惑度 p(step):越高表示越不确定。
3) 若 p(step) ≥ θ,则对该步骤重生成最多 K 次,选择困惑度最低的候选继续往下推理。
4) θ 控制“触发频率”,K 控制“最大分支数”:在准确率与推理耗时之间做折中。
四. 实验设计与评估
实验任务情景:股票投资建议与法律推理问答。
RQ1:预测/问答是否更准确?(Accuracy,部分任务还用 MCC)
RQ2:解释质量是否更好?(PROOF-Score:RC/DS/FA)
RQ3:在搜索策略上,是否能在“效果-耗时”之间达到更优折中?(不同 search 方法对比)
对比实验(1):预测/问答准确率
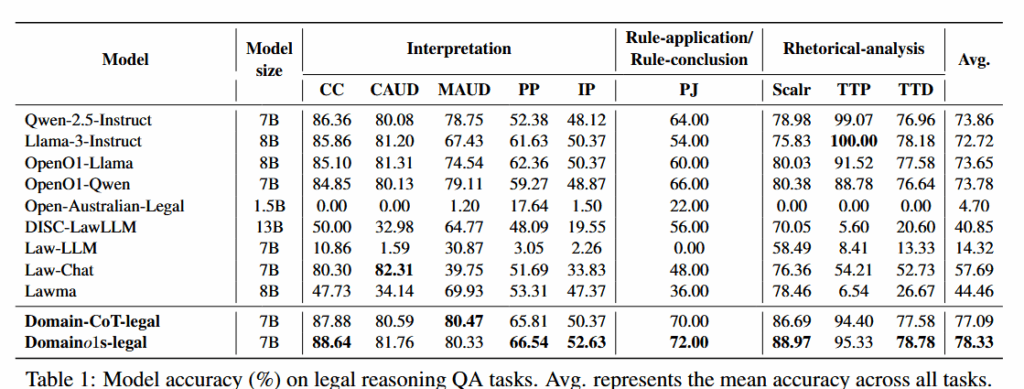
(1)法律 QA:Domaino1s-legal(7B)在多个子任务上达到更高平均准确率(Avg≈78.33),优于 Domain-CoT-legal(Avg≈77.09)和多种法律模型。
(2)金融预测:Domaino1s-finance 在 Accuracy 与 MCC 上小幅但稳定优于基座与若干金融模型基线。
(3)训练/推理配置:基于 Qwen-2.5-Instruct;SFT lr=5e-5,epoch=120,max_len=2048;推理时 θ=1.1,K=2。
对比实验(2):不同搜索策略的“效果—耗时”折中
Selective Tree Exploration 在显著降低耗时的同时取得更高准确率(相同 beam 设置)。
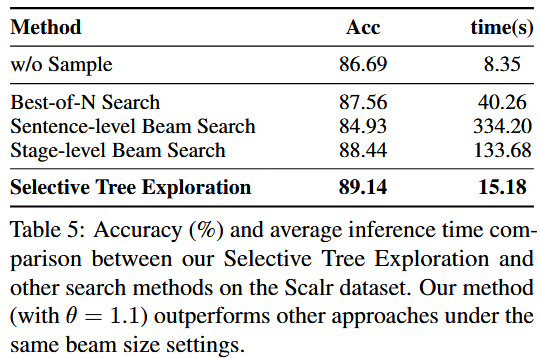
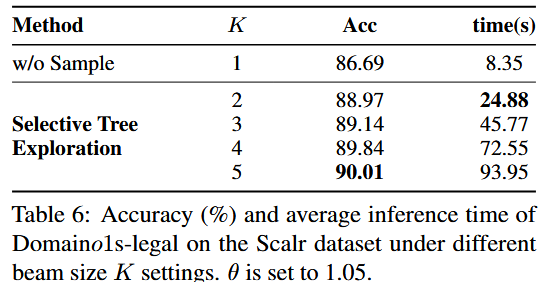
消融实验:分支数 K 增大 → 准确率上升但耗时快速增长
PROOF-Score:GPT-4o 评分(1~7),综合 RC/DS/FA;无解释输出记 0 分。
金融与法律任务上,Domaino1s 的 PROOF-Score 均为最高(表 4)。
注意:严格唯一答案任务需与 Accuracy 联合使用,避免“逻辑清晰但结论错误”的偏高分。
人类对齐:论文邀请金融/法律方向博士参与评分,整体趋势与 GPT-4o 评委接近,但关键场景建议专家 in-the-loop。
五. 对齐思考
技术创新——逻辑思维推理框架:将逻辑推理链变得可控,把评分过程拆成“可复用步骤模板”(规则定位→证据对齐→分项打分→风险/合规→总分/等级);借鉴 PROOF 的多维 rubric 思想,把完整性、合规性、事实性等一些维度映射到评分维度,实现开放式任务的可解释质量评价。
技术目标——专业手册公众服务:模型不仅给出结论,还能明确引用依据、解释扣分点、提示风险与合规要求,把分散的专业知识转化为公众可理解、可追溯的服务输出,提升透明度与可信度,并为人工复核与责任界定提供结构化证据链。
场景功能——食养通评分&识别品类功能:将品类识别 + 质量评分统一到同一条推理链:先做品类和子类判定,再按一些必要的既定规则完成风险项识别、合规核查与分项评分,最终输出总评分与评级,并同步给出可解释的扣分依据与改进建议;当证据不足或规则冲突时触发局部重生成或请求补充信息,保证评分稳定性与可审计性。
评论